With the Ontology being our mycorrhizal fungal network, naturally, we will need to interact with our data. There are almost innumerable ways to interact with the ontology, but today I’ll talk about my current favorite technique. It’s pretty common to connect your source data, pipeline it into a dataset and then use that as the backing of your ontology object types. (Foundry 101)
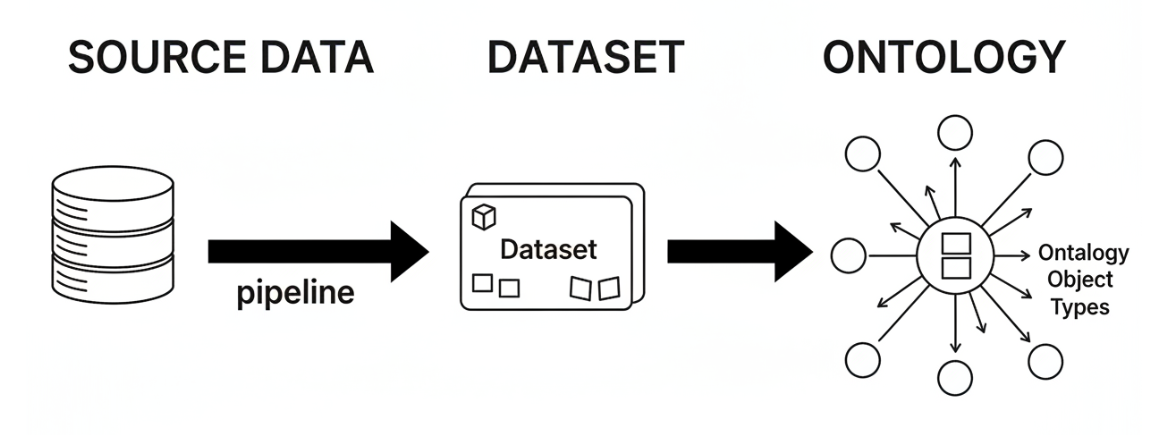
but what if you want to reverse the process, get your objects out (and user edits) and bring them into some other data location (through our friendly fungal network, into a Postgres Database).
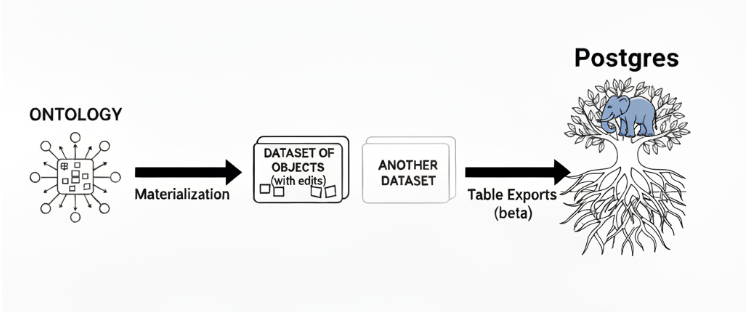
One way to do this is through Materialization
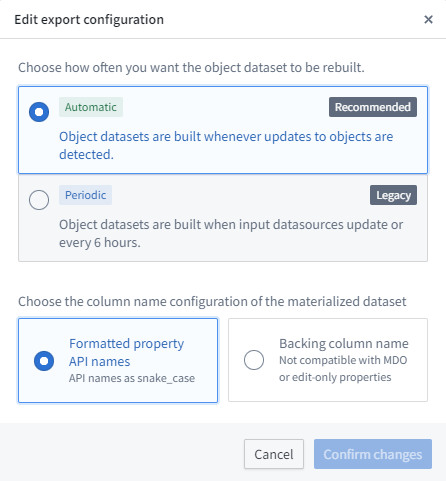
This creates a dataset of your objects (with edits) that then you can pipeline to another dataset (if needed) and then use a new beta feature ‘Table exports’ (It supports MSQL server, Postgres, Oracle, and some SaaS)

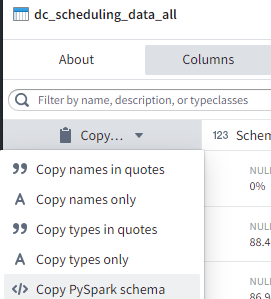
The schema needs to match EXACTLY, so my easy button is to go to the dataset, click on Columns and then Copy PySpark schema. I then copy this into an LLM and ask it to convert it to a postgres table creation script, easy-peasy. (Timestamps as timestamptz)
Like this (I’m tickled by the elephant in the tree)
Once I do this, I can then easily create some Grafana dashboards off my Postgres data
(If systems are trees, then dashboards are the flowers, ecologically speaking, amiright?)
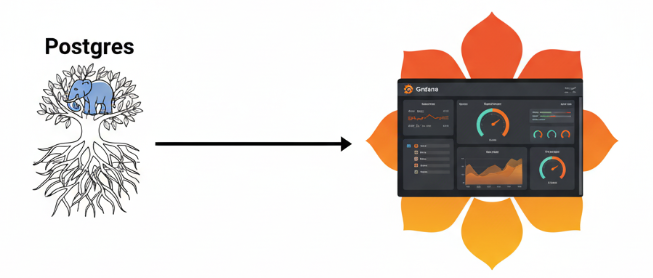
I really want to connect Grafana directly against the ontology, that might be my next exploration.
Another technique is to create a ‘queue’ object and then sync it down to be acted upon, similar to oracles ‘Interface Tables’ approach.
