http://bi-review.blogspot.com/2013/08/few-tips-for-dealing-with-large.html
Few tips for dealing with large QlikView applications
Tip #0 — go to Document Properties and turn off compression. It will make saving and loading application much faster. Yes, it takes more disk space now but you’re not going to send such large application by mail anyway.
Mitigate long reload times
Once you’ve got tens of millions of records you probably don’t want to perform full reload after every small change in the script. Some people use built-in debugger for limited runs, although you can have better control over limited reloads using a variable and FIRST prefix for LOAD statements that operate with large tables. Example:
LET vFirst = 1000;//00000000;
FIRST $(vFirst) LOAD …
In this case you can do quick short runs with a limited set of data either to check correctness of script syntax after small changes or verify transformation logic. Remove semi-colon and double slash for a full load. Make sure that you have enough zeroes.
You would probably want to reduce even full reload times as much as possible. In some cases, if data model allows logical partitioning of data it’s better to switch to partial reload as the main reload mode for updating the application with new information. In this case data model isn’t dropped entirely, so you can append new chunks of data to it instead of building everything from scratch. Full reload can be left for emergency cases, when entire data model has to be rebuilt.
This technique is especially useful when you work with monthly (weekly, daily) snapshots and you need to join them (you might want to do this for denormalization as a way of performance improvement discussed below). In this case instead of joining two full tables you can join monthly snapshots first, and then concatenate results month by month, using partial reloads (see picture below).
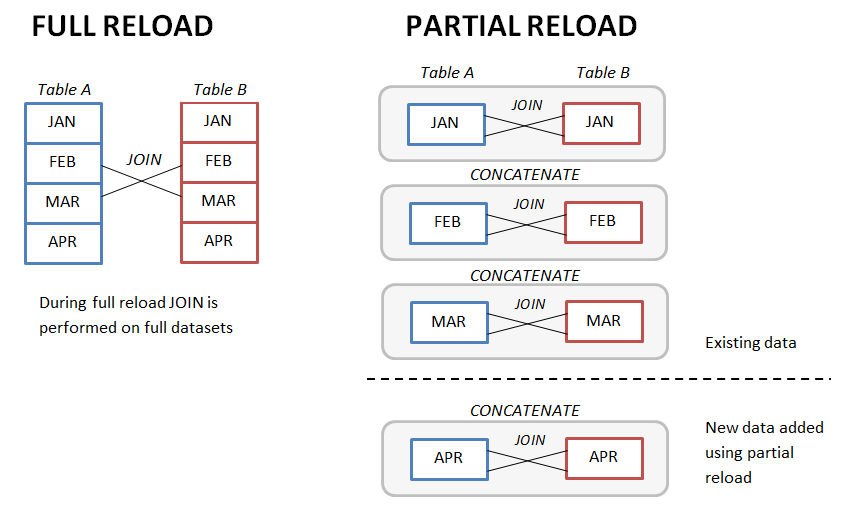
To make it more manageable, it’s better to store monthly snapshots in individual QVD files — one QVD per month.
Minimize memory usage
Large amounts of data require better control over memory usage. QlikView helps a lot by automatically detecting data types in source data. However QlikView not always does it correctly and sometimes it allocates more memory for a field value than it really is necessary. On a smaller data sets it’s not critical, however such sub-optimal data allocation might have significant impact on a large data volume. This behavior comes from the fact that QlikView basically has 3 data types:
- Number
- Text
- Dual
Numbers can be of several types (integer, float) and take from 4 to 8 bytes of memory. Text is just a string of text symbols and it can be of any length. Dual is a combination of a number and a text and is often used for representation of dates or custom number formats.
From these 3 types, the dual is the most memory-consuming type since it’s redundant and stores two representations of the same value. The problem with dual is that when QlikView is not sure about type of data being loaded it automatically assumes it’s a dual, even if it actually is a number. This leads to situations when otherwise regular numbers start consuming 20 or more bytes instead of 8 when loaded, because QlikView stores them as duals with both 8-byte value and its human-readable text representation which can be rather lengthy. Therefore, our goal is to make sure that dual is used only when it is really required, e.g. for date fields. We can achieve this by checking out the memory statistics and hinting QlikView about correct data types in the loading script.
To obtain memory statistics go again to Document Properties, press Memory Statistics button and save the .mem file.

When you got the .mem file — open it in Excel. It’s a standard tab-delimited text table so importing it shouldn’t be a problem. Once imported, look at the rows with Class = Database. It also makes sense to sort records by descending Bytes to focus on the most memory-consuming fields first.
In the example below you can see memory statistics for two fields — Product Name and DeviceID. Average length of a Product Name value is 46 bytes which is a lot but we can’t do much with it since this is a text field, maybe only remove extra spaces (if any) using TRIM( ). Values in the other field (DeviceID) contain only digits and therefore are actually numbers. However, for some reason, QlikView quietly decided to use dual type for them and therefore values in this field take 18 bytes on average. With specifying explicitly (using NUM() ) that values in this field are numbers we hint QlikView to use correct data type for it and achieve 55% reduction in memory consumption since each DeviceID value now takes only 8 bytes (see picture below).

Denormalize data model
Besides memory consumption, another challenge that comes with big data volume is increased calculation time. QlikView users and developers are a bit spoiled in this regard as they used to sub-second responses and often get annoyed when calculation times exceed 7-10 seconds which would still be considered as acceptable response time with other BI tools.
One of ways to reduce calculation times is denormalization of the data model. Although, there should be a reasonable balance since denormalization usually increases memory consumption.
For denormalization you need to examine expressions in the application and make sure that each expression uses as few tables as possible because going across table links greatly increases calculation times. In the example below, we have 3 tables and the most common calculation is “average customer age by product” since we use this application to perform demographical analyzis. The best way would be to move Age into Fact table, even if it breaks logical groupings and doesn’t look nice.

Upgrade hardware
And the last but far not least — consider upgrading the hardware. Keep in mind that heavy transformations, e.g. joins, may take significant amount of memory, sometimes up to 20 times of the resulting application size. In my case, the application was around 4GB but because of joining two large tables in the loading script it could take up to 100GB while reloading (another reason to use partial reloads). Interesting observation — reloading by the means of QlikView Server seems to be more efficient as it takes less memory compared to reloading in QlikView Desktop. The above mentioned application took only 80GB when reloaded on server.
For faster calculations consider having more CPUs. QlikView very efficiently uses parallelization across multiple CPU cores so having twice more CPU cores would noticeable reduce response times even with the same amount of RAM.
