Data Pipelines are pretty cool, but there are a some ‘nerd knobs’ that can be hard to find. I’ll show a few we have discovered. Credit to Javier Murrieta for the first two!
One quick way to get your feet wet is with the ‘Load data from S3 into redshift’ template
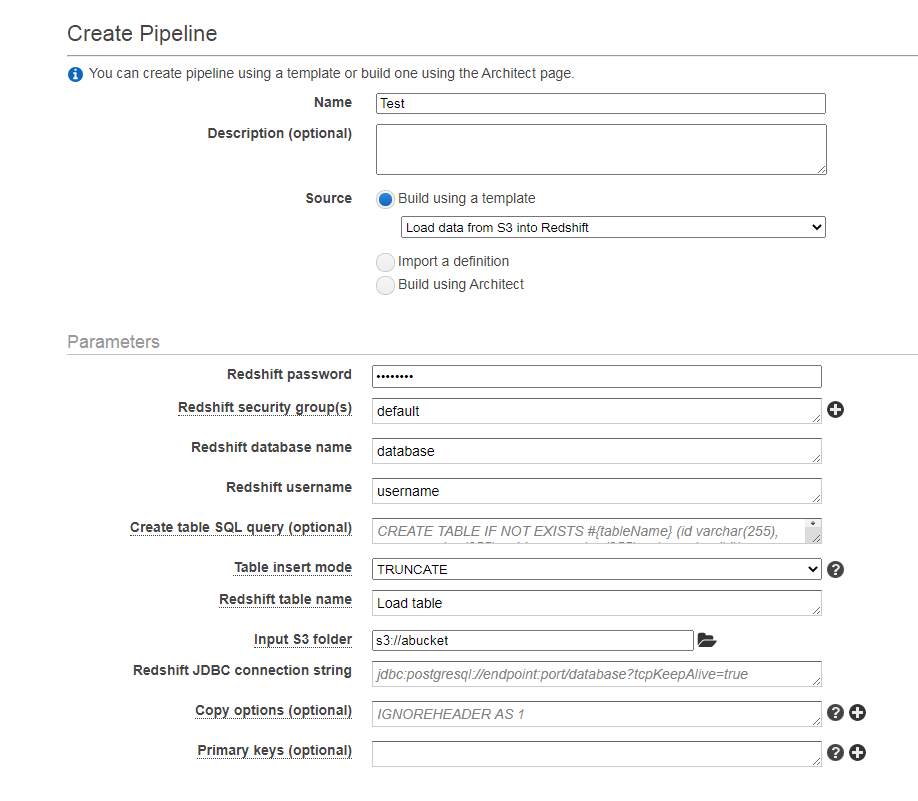
A common pattern is doing a redshift ‘upsert’ using a staging table
https://docs.aws.amazon.com/redshift/latest/dg/t_updating-inserting-using-staging-tables-.html
After creating this pipeline, you might be wondering how to ingest a gzip compressed file.
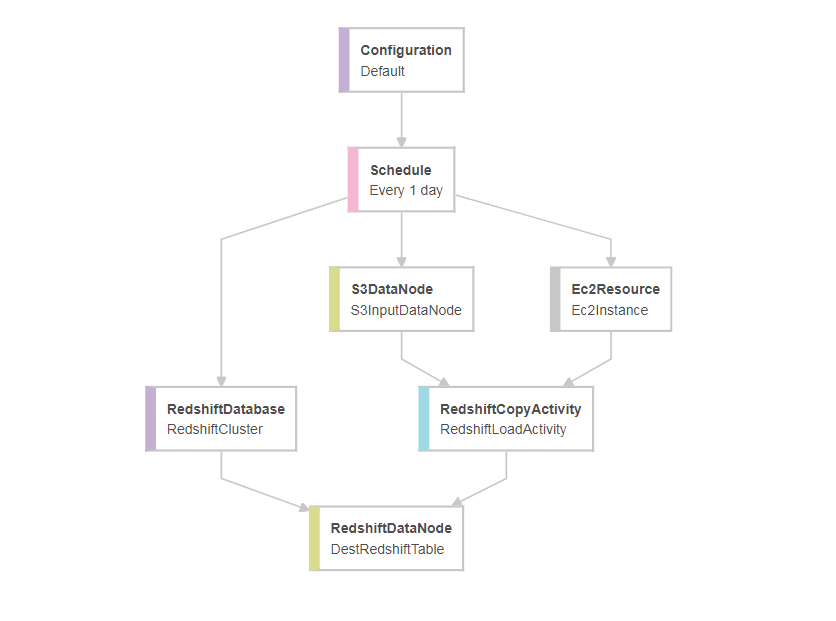
To do so, click into your S3InputDataNode, and do the ‘Add an optional field’
Choose compression, and type, GZIP

Another useful thing is to be able to change from the default schema.
This is under the RedShiftDataNode under DestRedshiftTable
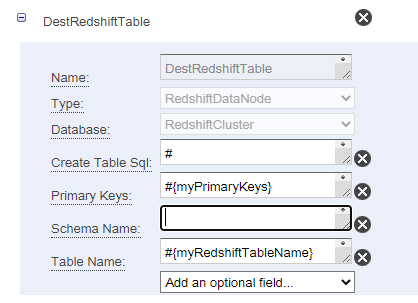
The final thing I wanted to do was connect to a redshift cluster inside a VPC. This article explains how to do it in the pipeline config
https://docs.aws.amazon.com/datapipeline/latest/DeveloperGuide/dp-resources-vpc.html
But, it is located in the UI under Ec2Resource, you have to add the subnet and Security Group ID
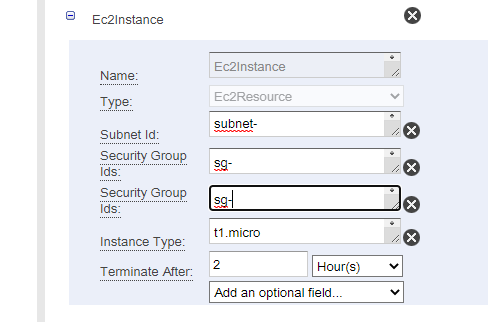
There you have a couple of useful settings
